If you are tracking OpenAI model series, then you must have seen OpenAI release o1 three months ago. On December 2034, OpenAI announced its next-level model, o3, which is one step closer towards the AGI (Artificial General Intelligence). But wait, did you miss anything? I mean, did you miss when o2 was launched? The answer is ‘No’; you did not miss anything. OpenAI decided to skip the “o2” designation in naming its latest AI model, o3, primarily to avoid confusion and potential trademark conflicts. This decision was partly made out of respect for a British telecommunications company that holds a trademark on the “o2” name, as well as to emphasize the significant improvements and capabilities of the new model compared to its predecessor.
Fair enough, back to the topic. Most of the advancements in the new model are the improvements in the benchmarks if we compare it with o3. That we will see in a bit. But important aspects I would like to call out here are the extension of the benchmark, which is the introduction of a prestigious AI reasoning test called ARC (Abstraction and Reasoning Corpus), and the second one is the safety testing program, which, not only improves its robustness but also enhances its trust in the user community. Before understanding these two in more depth, let us first see, briefly, what o3 is. And how it is better than o1.
‘o3’ model is a successor to the earlier o1 model and is designed to tackle complex reasoning tasks with improved performance across various domains, including coding, mathematics, and science. OpenAI is going to release two versions, o3 and o3 mini, which are cost-effective sibling of o3. Here is the brief summary of benchmark performance advancements as compared to o1:
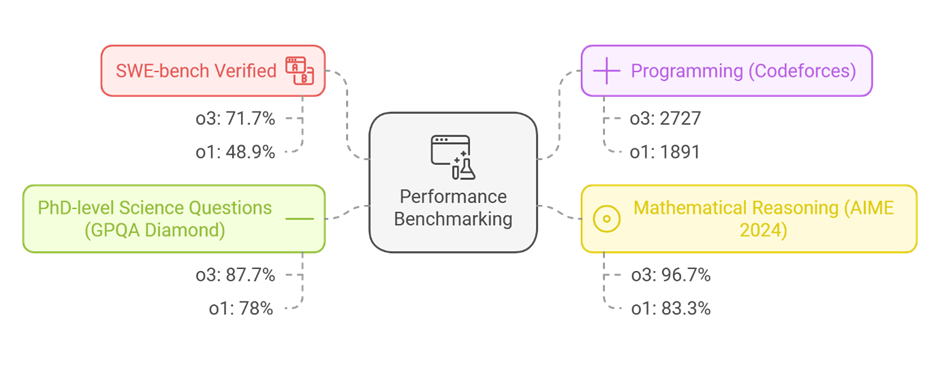
Benchmark Performance: In several key benchmarks, o3 has outperformed o1 significantly.
- SWE-bench verified: o3 scored 71.7%, compared to o1’s 48.9%.
- Programming (Codeforces): o3 achieved an ELO rating of 2727, while o1 scored 1891.
- Mathematical Reasoning (AIME 2024): o3 secured 96.7% accuracy versus o1’s 83.3%.
- PhD-level Science Questions (GPQA Diamond): o3 scored 87.7%, surpassing o1’s 78%
I will not go in the depths of all the benchmarks, but I would like to touch on two important aspects that inch this model towards AGI, which is the ultimate goal of all AI endeavors.
- Introduction of ARC AGI benchmark and
- Deliberative Alignment
What is ARC AGI?
The Abstraction and Reasoning Corpus (ARC) is a benchmark designed to evaluate the reasoning capabilities of artificial intelligence systems. ARC was developed by François Chollet (BTW, François Chollet is the creator of Keras, a deep learning library) in 2019. ARC aims to measure the gap between human and machine intelligence, particularly in tasks that require abstract reasoning and problem-solving skills.
ARC serves as a test for AI skill acquisition, focusing on how well AI can learn and generalize from limited examples to solve novel tasks. It is structured to challenge algorithms in ways that traditional benchmarks do not, emphasizing the need for fluid intelligence rather than rote learning. See below to understand it.
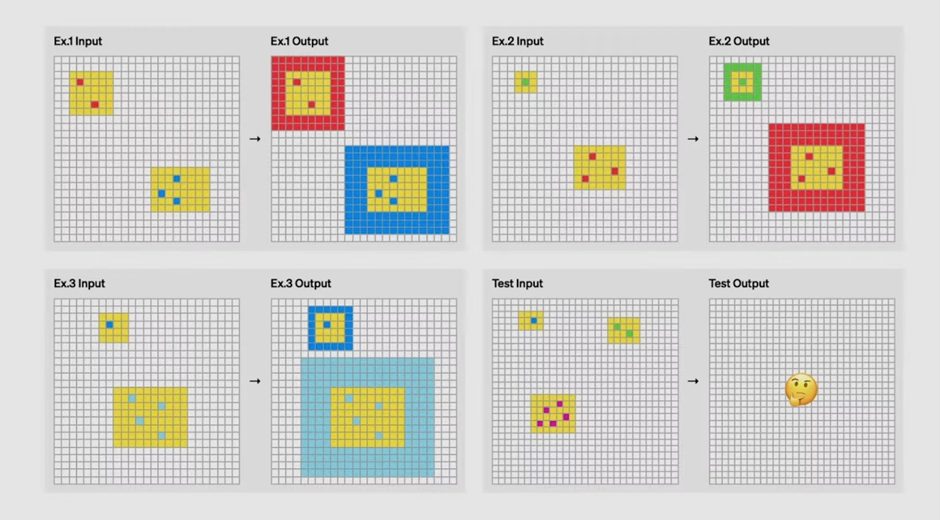
Source: https://www.youtube.com/live/SKBG1sqdyIU
On the top left, can you guess the rule what turns input to output? Such task can be solved by humans using the intution but making it difficult for the machines to learn.
What makes ARC AGI particularly difficult is that every task requires distinct reasoning skills. Models cannot rely on memorized solutions or templates; instead, they must adapt to entirely new challenges in each test. For instance, one task might involve identifying patterns in geometric transformations, while another could require reasoning about numerical sequences. This diversity makes ARC AGI a powerful measure of how well an AI can truly think and learn like a human.
How o3 beat humans in this task?
o3 achieved a state-of-the-art score of 75.7% on the Arc AGI semi-private holdout set with low compute7. When given high compute, O3 scored 87.5% on the same hidden holdout set, which is above the human performance threshold of 85%.
This benchmark tests the model’s ability to learn new skills on the fly rather than repeating memorized information. That’s what makes it closer to AGI
What is Deliberative Alignment?
Any model to be trusted for use in any big organization needs to provide systematic guidelines the model is using to make ‘it’safe to use’ for any company. Here ‘Deliberative Alignment’ comes. Usually, safety measures are written guidelines for what should be done and what should not be done. But can all guidelines be written? The answer is ‘No’. Hence the model should have the capability to look at the prompt and tell whether its safe or not based on the reasoning, not on the provided guidelines.
A new safety technique called deliberative alignment leverages the reasoning capabilities of models to establish a more accurate safety boundary. This method allows the model to analyze prompts and determine if they are safe, even if the user is trying to trick the system. This is done by having the model reason over the prompt and identify hidden intents. This has shown improved performance in accurately rejecting unsafe prompts without over-refusing safe prompts.
Mechanism: During the chain-of-thought reasoning process, o3 recalls relevant sections of OpenAI’s safety policy. For example, if prompted with potentially harmful requests, the model can identify the nature of the request and appropriately refuse to assist, as demonstrated in scenarios where users attempt to elicit unsafe information.
Performance Improvements: The implementation of deliberative alignment has reportedly led to a significant reduction in unsafe responses. For instance, o3 is designed to better resist common attempts to manipulate its outputs (known as jailbreaks) while also being more permissive with benign queries. This dual capability enhances its overall alignment with safety principles.
By ensuring that models can effectively reason about their responses in relation to established safety policies, OpenAI aims to create AI systems that are not only powerful but also responsible and aligned with human values. As o3 continues through its testing phases, further insights into its safety performance will emerge, shaping the future of AI deployment in sensitive applications.
In conclusion, OpenAI’s O3 sets a new benchmark in the journey toward AGI. By excelling in reasoning tasks through ARC and ensuring safety with deliberative alignment, it redefines the standards for intelligent systems. O3 is not just another model; it’s a step closer to bridging the gap between human and machine intelligence, paving the way for responsible AI innovation.
Read more on o1 in the previous blog post:
References:
1. https://www.youtube.com/watch?v=vswFf5XxJ2M
2. https://www.datacamp.com/blog/o3-openai


