Even though all LLM’s are trained on whole world’s data but still you do not get the answers specific to your organization. For example, you can get the answer on what compliances are required to train a model on public data but you will not get the answer on ‘what compliances my company adheres to and what else can be done?’. This is company specific result that LLM’s cannot answer as its not trained on YOUR data. But there are ways you can get outputs based on the data specific to your organization.
How this can be done?
Broadly, there are two ways when we can get specific results. Creating RAG application and fine tune LLM’s for your needs.
In this blog we will see:
- What these approaches are?
- What are their pros and cons?
- Use cases of RAG and Fine-tuned model?
- Which one is suitable for your organization?
What is RAG application?
Here is the definition given by the bentoml.
“Retrieval-Augmented Generation (RAG) is a widely used application pattern for Large Language Models (LLMs). It uses information retrieval systems to give LLMs extra context, which aids in answering user queries not covered in the LLM’s training data and helps to prevent hallucinations.”
It is very straight forward, which says that RAG application provides ‘extra context’ to LLMs to answer specific questions. And it prevents ‘hallucinations’.
Google Cloud says, ‘AI hallucinations are incorrect or misleading results that AI models generate. These errors can be caused by a variety of factors, including insufficient training data, incorrect assumptions made by the model, or biases in the data used to train the model.’
How RAG works?
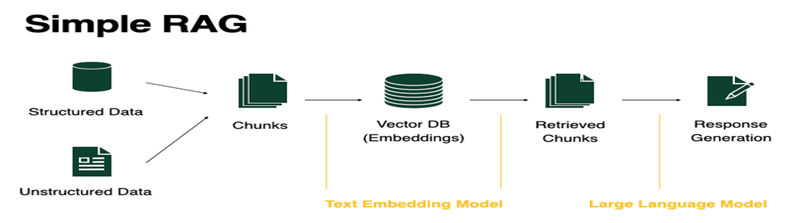
Step 1 and 2, create chucks from the data (structured or unstructured) from the overall corpus of data in any format like html, txt, csv, json, online data on website, youtube video data etc.
Step 3, create vector embeddings. A text embedding model steps in, turning each chunk into vectors representing their semantic meaning.
Step 4, These embeddings are then stored in a vector database, serving as the foundation for data retrieval.
Step 5, Retrieve required chuck from the vector store as per the used needs and respond to the request.
RAG application are easy to create and few line of python code using Langchain are capable of implementing RAG applications but there are some product challenges.
Challenges to RAG applications;
- Retrieval Performance: Not all data in the form of chunks is relevant which affects Recall and Precision of the model. Also, complex documents are difficult to feed into the model.
- Difficulty in response synthesis: Toxic or offensive user request is difficult to handle.
- Response Evaluation: RAG application responses and be done using LLM’s but its not easy
RAG Use Cases
- Chatbots and AI Technical Support
- Language Translation: RAG helps improve language translating tasks by considering the context element in an external knowledge base. By considering specific terminology and domain knowledge, this advanced approach leads to more accurate language translations. This is particularly useful in technical and specialized fields.
- Medical Research: RAG-powered systems provide access to up-to-date medical documents, clinical guidelines, and information that weren’t part of the LLM training dataset. As a result, these systems help medical professionals come up with accurate diagnoses and provide better treatment recommendations to their patients.
- Legal Research and Document Review: legal professionals worldwide can rely on RAG models to streamline legal document review processes and conduct effective legal research. These models can help in analyzing, reviewing, and summarizing a wide variety of legal documents, such as contracts, statuses, affidavits, wills, and other legal documents, in the shortest time possible.
What is Fine-Tuning?
Fine-tuning refers to the process of training a large language model that has already been pre-trained to help improve its overall performance. By fine-tuning, you’re simply adjusting the model’s weights, architecture, or parameters based on the available labeled data, making it more tailored to perform specialized tasks.
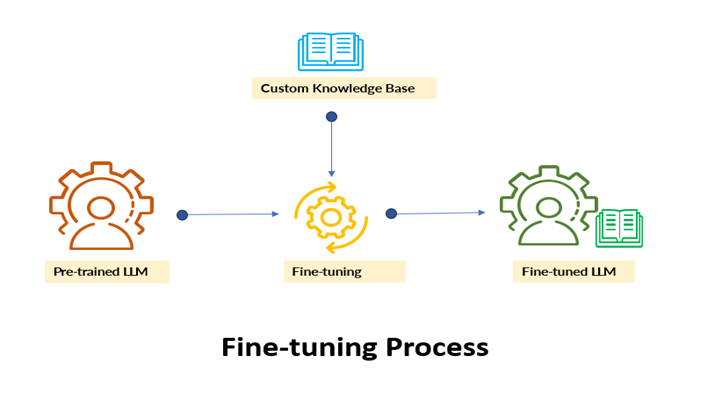
Fine-tuning use cases:
- Sentiment analysis: Fine-tuning an LLM can help improve its capabilities in determining the attitude and emotion expressed in each text. the LLM will be able to deliver the most accurate sentiment analysis from online reviews, customer support chat transcripts, and even social media comments. With the help of accurate sentiment analysis, organizations are able to make more informed decisions regarding their products and customer service to boost customer satisfaction.
- Named-entity recognition (NER): This is another strong case of using fine tuned model. fine-tuning will allow an LLM to easily recognize specialized entities such as legal jargon or even specialized medical terms, thus improving its NER capabilities.
- Personalized content recommendation: Providing content suggestions that match a customer’s specific needs creates a sense of personalization and makes the customer feel understood and valued.
Which one is suitable for your organization?
Retrieval-Augmented Generation and fine-tuning are two completely different approaches to building and using Large Language Models (LLMs). There are various factors you need to consider when choosing between RAG and LLM fine-tuning as your preferred LLM learning technique.
1. Dynamic Vs Static: Generally, RAG performs exceptionally well in dynamic settings. This is because it regularly requests the most recent data from external knowledge bases without the need for frequent retraining. This ensures that the information generated by RAG-powered models is always up-to-date. In contrast, fine-tuned LLMs often become static snapshots of their training datasets and easily become outdated in scenarios involving dynamic data. Additionally, fine-tuning isn’t always reliable since it sometimes doesn’t recall the knowledge it has acquired over time.
2. Training Data: A mix of supervised and labeled data that shows how to appropriately obtain and use pertinent external information is frequently used by RAG LLMs. This clarifies why retrieval and generation are tasks that RAG-powered models can manage with ease.
Fine-tuned LLMs, on the other hand, are trained on a task-specific dataset that mostly consists of labeled samples that correspond to the target task. Although refined models are tailored to carry out different NLP tasks, information retrieval is not their primary purpose.
3. Model Customization and Complexity: RAG models mainly focus on information retrieval and may not automatically adapt their linguistic style or domain specialization based on the information obtained from an external knowledge base. Fine-tuning allows you to adjust an LLM’s behavior. RAGs are less complex than fine-tuned
4. Hallucination: RAGs are less prone to hallucinate than fine-tuned models
5. Transparency: RAG provides more transparency by splitting response generation into different stages, providing valuable information on data retrieval, and enhancing user trust in outputs. In contrast, fine-tuning functions like a black box, obscuring the reasoning behind its responses.
6. Cost: Finally, its cost that allows any use case to be feasible to pursue or not. RAG is less expensive than fine-tuning procedures because it requires fewer labeled data and resources. Most RAG setup costs are related to retrieval and embedding systems.
More labeled data, substantial processing power, and cutting-edge hardware—such as high-performance GPUs or TPUs—are needed for fine-tuning. Because of this, fine-tuning is more expensive overall than RAG.
Based on use cases, resources and priorities, any technique can be adopted. Most of the cases can be implemented using RAG but, if use case demands model to be static and needs to be complied with certain laws, fine-tuned model can be used. Fine-tuning is also a great fit for overcoming information bias and other limitations, such as language repetitions or inconsistencies.
References:
https://www.databricks.com/glossary/retrieval-augmented-generation-rag
https://addepto.com/blog/rag-vs-fine-tuning-a-comparative-analysis-of-llm-learning-techniques/#:~:text=RAG%20and%20fine%2Dtuning%20differences,trained%20LLM%20for%20specific%20tasks.https://www.bentoml.com/blog/building-rag-with-open-source-and-custom-ai-models


